最近、過去に放送していたアニメをYoutubeで公開するフル☆アニメTVというチャンネルが存在することを知り、動画として保存したいと思いました。
ただ、動画は1本に対して複数話まとめているため、できれば話数毎に保存できないかと考えました。
そこで、保存した動画に対して特定シーンの情報(フレーム)を元にトリミングと書き出し処理を実行すれば実現できるのではないかと考え検討することにしました。
作成したもの
動画ファイルの読込み、分析、タイムスタンプ作成、書き出しを順番に実行するコードをPythonで作成しました。
作成したコードはGitHubにコミットしていますので合わせて参照ください。
処理の流れ
- 動画のフレーム情報をopencv-pythonとnumpy、pytesseractを使用して分析
- 分析した情報を元にトリミングするタイムスタンプを作成
- タイムスタンプを元にMoviePyまたは、QuickTime Playerを使用してトリミング処理と書き出し処理を実行
詳細
動画のフレーム情報をopencvとnumpy、pytesseractを使用して分析
フレーム情報の分析は比較用の画像を用意して行います。
シーンの特定として以下の処理を行います。
① 画像の類似度を計算し、設定した閾値以上か判定する
事前に格納した比較元画像に対して切り出しと二値化処理(バイナリ閾値:cv2.THRESH_BINARY)を行い、ヒストグラムを計算する
1秒毎に取得した画像に対して1.と同様の処理を行い、ヒストグラムを計算する
1.と2.のヒストグラムの相関係数(cv2.HISTCMP_CORREL)を計算して類似度を計算し、事前に設定した閾値値以上から判定する
② ①の条件を満たした画像に対してOCRで事前に設定した文字列に一致するか判定する
2つの処理を実行する理由は、ヒストグラムだけでは条件を満たさないケースがあったため、OCRも追加することにしました。
分析に使用する比較元の画像ファイルは指定フォルダに格納し、パスと各判定処理で使用する設定値をTOMLファイル(setting.toml)に定義して読み込みます。
なお、ヒストグラム、OCR処理は単独でも実行できるように実装しています。
その他、1秒ごとに解析するのは処理負荷が高いため、フレームを読み飛ばす処理も追加しています。詳細はREADME.mdを確認ください。
分析した情報を元にトリミングするタイムスタンプを作成
タイムスタンプはトリミングの開始と終了をセットとし、セグメント毎に管理するため二次元配列で作成します。
タイムスタンプは対象画像毎にリストに追加しますが、同一の対象画像が続けて条件を満たす場合があります。(例:アニメのエンドロール)
この場合は最初に条件を満たしたフレームのタイムスタンプだけ格納できれば良いため、どの対象画像を処理中かどうかを管理するフラグ変数を対象画像毎に保持するリストで作成し、異なる画像が条件を満たした場合にフラグをオン(TRUE)、オフ(FALSE)で切り替えることで同一画像のタイムスタンプは格納しないように制御します。
タイムスタンプを元にMoviePyまたは、QuickTime Playerを使用してトリミング処理と書き出し処理を実行
トリミング処理と書き出し処理はMoviePyまたは、QuickTime Playerの仕様に従います。
MoviePyの詳細はGitHubを参照ください。本コードではwrite_videofileメソッドを使用します。 また、MacでもMoviePyは使用できますが、QuickTime Playerの方が処理が速いため、Applescriptから実行する方法で対応しました。 コードは以下リポジトリのコードを移植し、コマンドラインで実行するように変更しました。
動画への適用
作成したプログラムをいくつかの動画に対して使用しました。 対象の動画は頭文字Dというアニメで4th stageの動画に対して確認しました。
動画は3話分合わせた動画が1本の動画として公開されていました。
対象とする動画は著作権がありますので伏せますが、第1話から3話の動画で再生時間は01:22:45です。
本記事を公開時点では動画は公開されていますが、公開期間が設けられていますので、使用する際はご注意ください。
実行環境と設定
比較元の画像として、以下のOPとEDの画像を使用します。
さらにOCRするため、OP画像では"車"、EDでは"企"を認識対象とします。
また、ED画像については切り取り処理をしてOCRの認識範囲を狭めます。
切り取り処理をする理由はエンドロールで"企"という文字が存在し、エンドロール途中でタイムスタンプを保存することがあったため、終了時間を正しく決定できるようにします。


動画解析に使用する情報(setting.toml)は以下の通りです。
実行結果
結果は下記の通りです。うまく3分割できています。
| 話数 | 再生時間 |
|---|---|
| 1話 | 27:18 |
| 2話 | 27:18 |
| 3話 | 27:18 |
OCRの認識結果は実行結果のログ(execution.log)から下記となりました。
2023-02-23 21:28:04,251 - INFO - log - ocr.py - ocr_frame - 63 - ocr_detect:登場する人物・地名・団体名はすべて架空のものです。車の運転は交通ルールを守り、安全運転を心がけましょう。 - seane1 2023-02-23 21:28:16,943 - INFO - log - ocr.py - ocr_frame - 63 - ocr_detect:製作トゥウーマックスナービー企画 - seane2 2023-02-23 21:28:18,292 - INFO - log - ocr.py - ocr_frame - 63 - ocr_detect:登場する人物・地名・団体名はすべて架空のものです。車の運転は交通ルールを守り、安全運転を心がけましょう。 - seane1 2023-02-23 21:28:31,026 - INFO - log - ocr.py - ocr_frame - 63 - ocr_detect:製作かたウゥウーマックスナービー企画 - seane2 2023-02-23 21:28:32,398 - INFO - log - ocr.py - ocr_frame - 63 - ocr_detect:この物語はフィクションであり、登場する人物・地名・団体名はすべて還空のものです。車の運転は交通ルールを守り、安全運転を心がけましょう。 - seane1 2023-02-23 21:28:46,315 - INFO - log - ocr.py - ocr_frame - 63 - ocr_detect:肌條かウーマックスナービー企画 - seane2
実際に適用すると認識文字列が異なることがわかります。
OCR処理は複数文字列を対象にする実装にしていますが、同じ認識結果にならないケースでは認識文字を増やすほど、条件を満たす対象が増えて、切り取りや二値化処理などの前処理を増やすことになり複雑になります。パラメータ設定としては認識対象文字はなるべく少なくするのが良いと感じました。
"車"と"企"の文字は含まれていますのでフレームに対応するタイムスタンプを元にトリミング処理が実行されました。
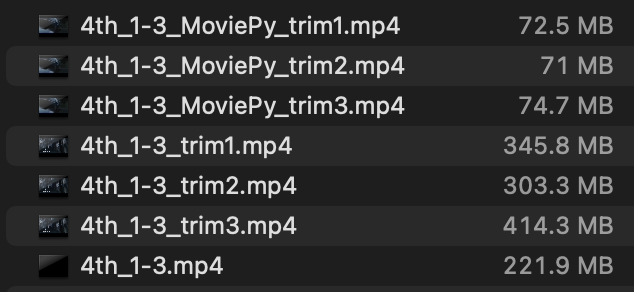
なお、上記結果の再生時間は同じ時間になっていますが、他の動画にも適用した結果は下記の通りです。
ファイル名とサイズを表示していますが、他の動画に対しても3分割できていることが確認できました。

ちなみに、プログラムではQuickTime Playerの解像度をexportの指定で640×360:480p(SD)にしてファイルの書き出しをしていますが、ファイルサイズが分割前よりも大きくなってます。これはQuickTime Playerによる書き出しの仕様による可能性がありますが理由はわかっていません。
export front document in outputFilePathForHFS using settings preset "480p"
ファイルの差異としてこちらの方の記事でカラープロファイルの差異について説明されていますが、mp4から480p指定でメディアエンコードすると拡張子がmovとなり、export処理と同様にサイズがmp4よりも大きくなりました。内部的に情報を付加する処理が動いている可能性があると思います。
なお、MoviePyを使用した場合は同様に解像度を480pとしましたが、ファイルサイズは元のファイルから約1/3となりました。
vide_clip_resized = video_clip.resize(height=360)
まとめ
動画ファイルのトリミングと書き出し処理を自動化する方法について紹介しました。
動画に適用する場合はsetting.tomlによる調整が必要であり、必ず適用できる保証はありませんが、個人的にはやりたいことは実現できました。
今後はこんなシーンが映ってる部分をカットしたいとか、文章ベースでできたら良さそうだなと考えています。
プログラムは他の動画に対しても適用できると思います。コードはコミットしていますので、是非使用してみてください。